|
I'm an incoming faculty member at (will announce soon). Previously I was a Postdoctoral Fellow at the Robotics Institute, Carnegie Mellon University, working under the guidance of Prof. László A. Jeni. I obtained my Ph.D. degree at Center for Research in Computer Vision (CRCV) at University of Central Florida (UCF) under the supervision of Prof. Chen Chen. Before joining UCF, I obtained my Master's degree at Tufts University in Aug 2019, advised by Prof. Shuchin Aeron and Prof. Eric Miller. I received my Bachelor's Degree at University of Bridgeport and Wuhan University of Science and Technology in June 2016. Email / Google Scholar / Resume / |

|
|
My research interests are Computer Vision, AIGC, and Vision Language Models. Specifically, I focus on:
Below is a selected list of my works. The full publication can be found on my Google Scholar page. If you are interested in these topics and want to work with me, please don't hesitate to reach out to me via email. |
|
|

|
Research Intern
Innopeak Tech, Seattle, USA. Summer 2022 Mentor: Guo-Jun Qi, Human mesh recovery for single images. |
|
|
|
|
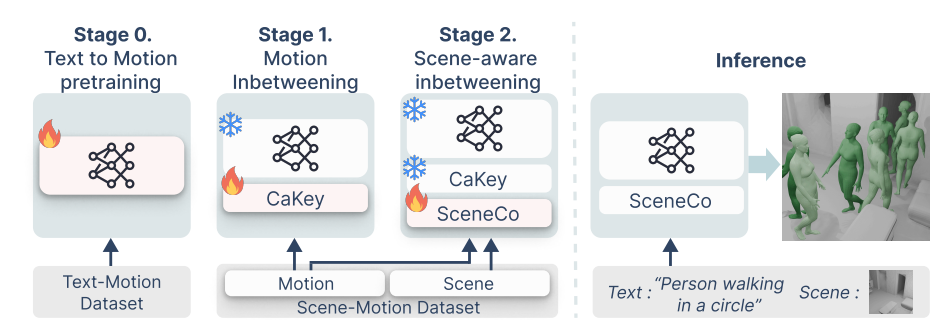
Jungbin Cho, Minsu Kim, Jisoo Kim, Ce Zheng, Laszlo A. Jeni, Ming-Hsuan Yang , Youngjae Yu, Seon Joo Kim. arXiv, 2025 paper / project page We introduce SceneAdapt, a framework that injects scene awareness into text-conditioned motion models by leveraging disjoint scene–motion and text–motion datasets through two adaptation stages: inbetweening and scene-aware inbetweening. |
|
|

|
Yiwen Zhao, Ce Zheng (project lead) , Yufu Wang, Hsueh-Han Daniel Yang, Liting Wen, Laszlo A. Jeni. IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2026 paper / project page We propose OnlineHMR, a fully online framework for global human trajectory and motion recovery. |
|
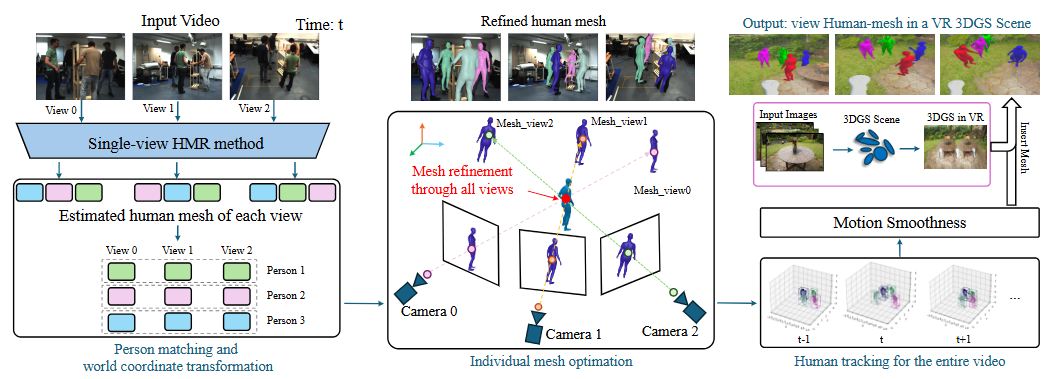
Yijie Li, Ce Zheng (project lead) , Yijie He, Joel Julin, Ryosuke Ichikari, Satoki Ogiso, Satoshi Nakae, Akihiro Sato, Takeshi Kurata, Laszlo A. Jeni. IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026 paper / project page We propose a 4D Human Motion Reconstruction Virtual Reality System that integrates advanced 4D multi-view human mesh recovery and high-quality 3D environment reconstruction using 3D Gaussian Splatting. |
|
Liuyue Xie*, George Z. Wei*, Avik Kuthiala*, Ce Zheng, Ananya Bal, Mosam Dabhi, Liting Wen, Taru Rustagi, Ethan Lai, Sushil Khyalia, Rohan Choudhury, Morteza Ziyadi, Xu Zhang, Hao Yang, Laszlo A. Jeni. The 40th Annual AAAI Conference on Artificial Intelligence (AAAI), 2026 paper / project page We introduce MAVERIX, a novel benchmark explicitly designed to evaluate multimodal models through tasks that necessitate close integration of video and audio information. |
|
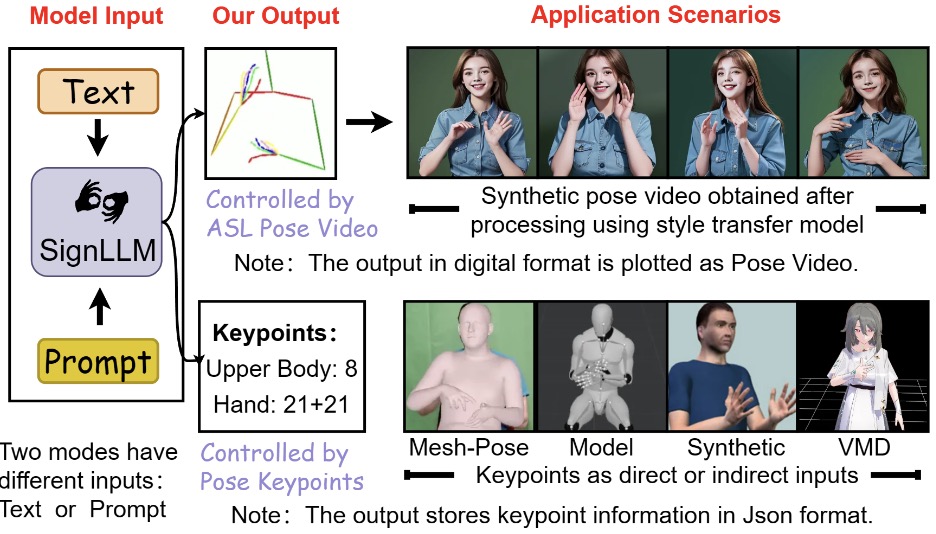
Sen Fang, Chen Chen, Lei Wang, Ce Zheng, Chunyu Sui, Yapeng Tian. ICCV Workshop (CV4A11y), 2025 paper / project page We propose SignLLM, the first multilingual Sign Language Production (SLP) model, which includes two novel multilingual SLP modes that allow for the generation of sign language gestures from input text or prompt. |
|
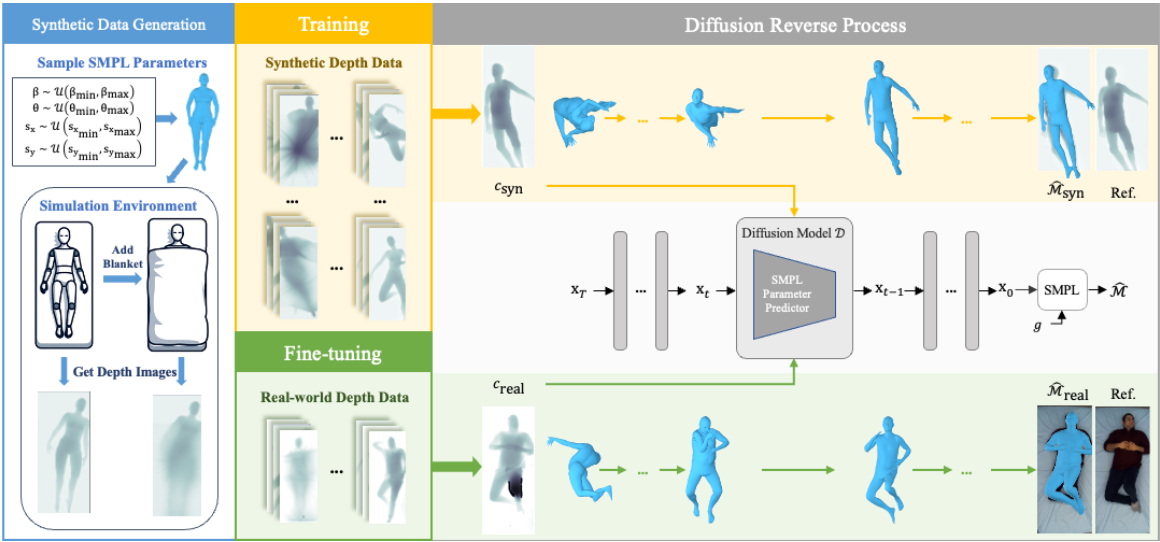
Jing Gao, Ce Zheng, Laszlo A. Jeni, Zackory Erickson. IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2025 paper / project page A diffusion-based sim-to-real transfer Framework for in-bed human mesh recovery from depth images. |

|
Ce Zheng, Xianpeng Liu, Qucheng Peng, Tianfu Wu, Pu Wang, Chen Chen. IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025 paper / project page A Diffusion-Driven Transformer-based Framework to decode specific motion patterns from the input sequence. |
|
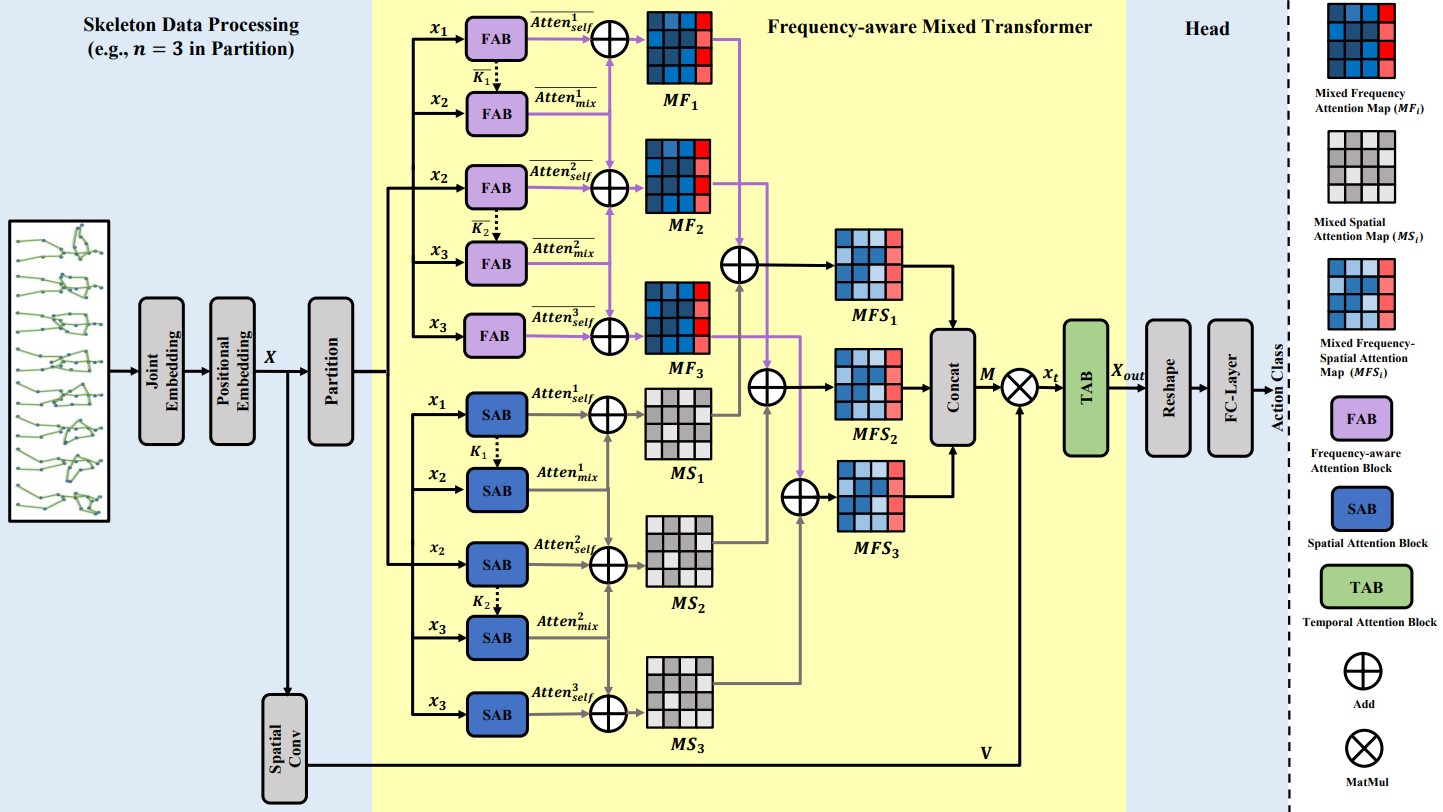
Wenhan Wu, Ce Zheng, Zihao Yang, Chen Chen, Srijan Das, Aidong Lu. ACM Multimedia (ACM MM), 2024 paper / project page Frequency-aware Mixed Transformer (FreqMixFormer) for recognizing similar skeletal actions with subtle discriminative motions. |
|
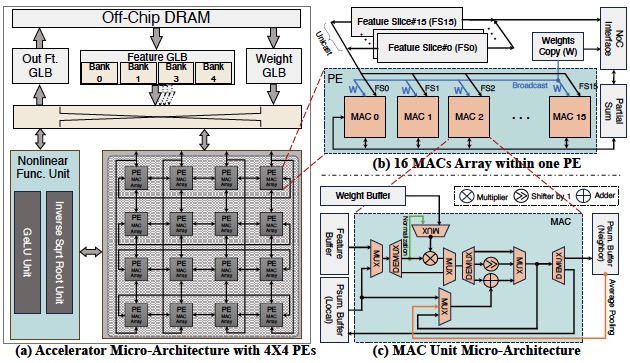
Shilin Tian, Chase Szafranski, Ce Zheng, Fan Yao, Ahmed Louri, Chen Chen, Hao Zheng. Design Automation Conference(DAC), 2024 paper / VITA, a hardware and algorithm co-design framework for ViT-based HMR with improved performance and energy efficiency |
|
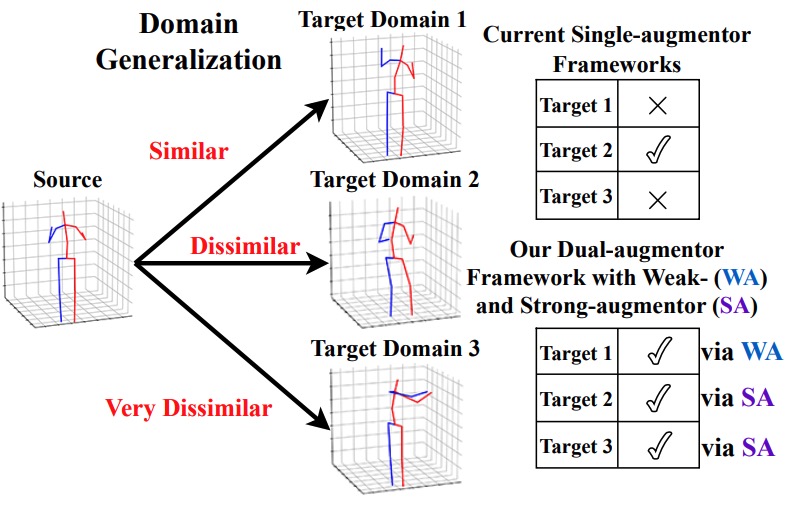
Qucheng Peng, Ce Zheng, Chen Chen. IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2024 paper / code / we propose a novel dual-augmentor framework designed to enhance domain generalization in 3D human pose estimation. |
|
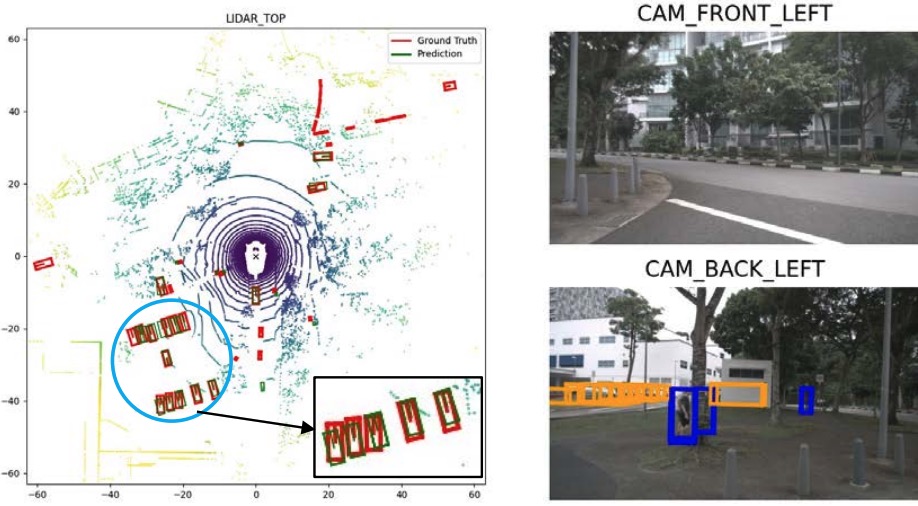
Xianpeng Liu, Ce Zheng, Ming Qian, Nan Xue, Chen Chen, Zhebin Zhang, Chen Li, Tianfu Wu. IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2024 paper / Project page / Multi-View Attentive Contextualization (MvACon), a simple yet effective method for improving 2D-to-3D feature lifting in query-based multi-view 3D (MV3D) object detection. |
|
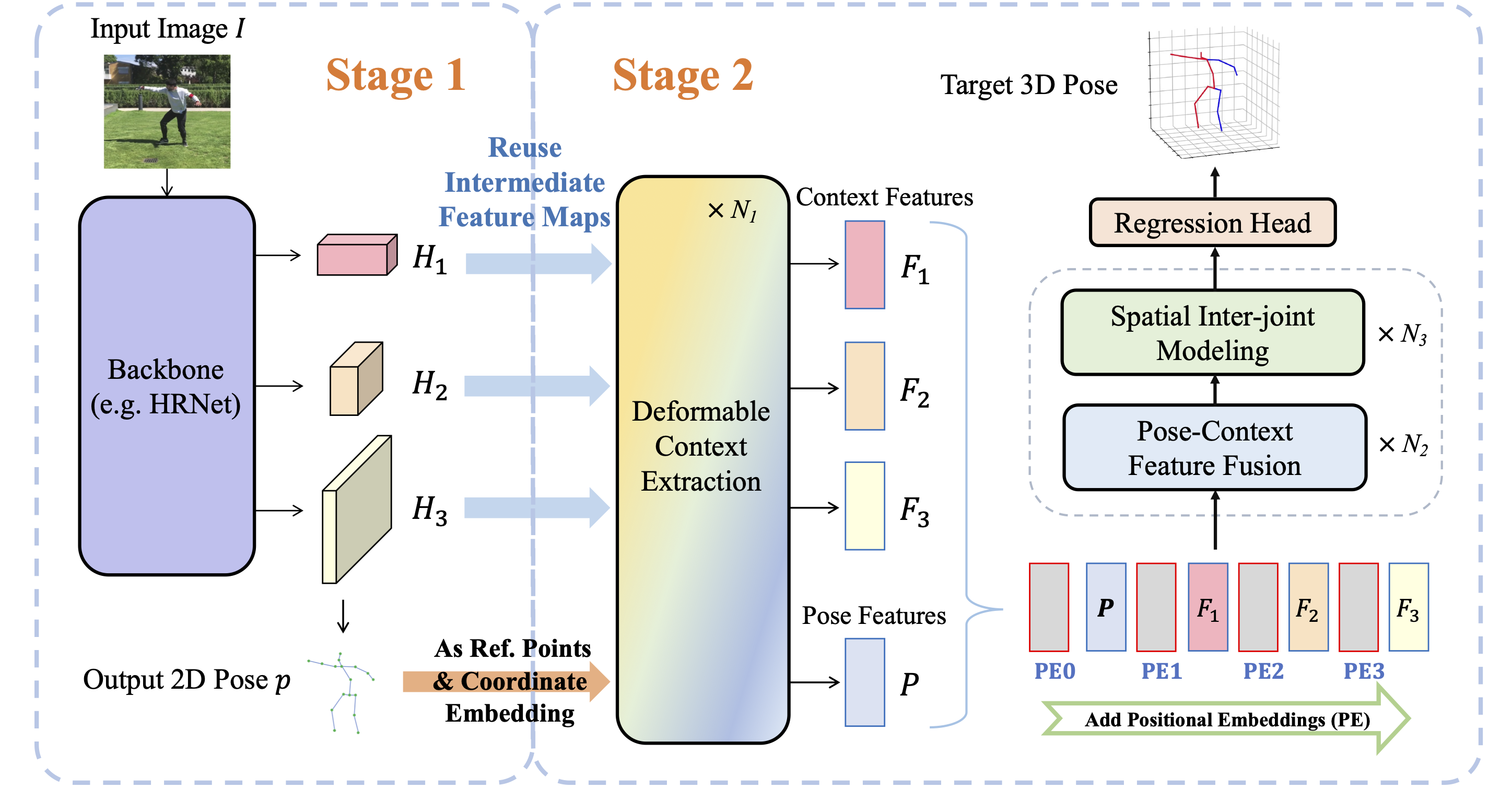
Qitao Zhao, Ce Zheng, Mengyuan Liu, Chen Chen. Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS), 2023 paper / project page We revisit the 2D-3D lifting pipeline, leveraging the readily available intermediate visual representations. |

|
Xianpeng Liu, Ce Zheng, Kelvin Cheng, Nan Xue, Guo-Jun Qi, Tianfu Wu. IEEE/CVF International Conference on Computer Vision (ICCV), 2023 paper / Code MonoXiver: leverages the self-attention mechanism for proposal verification, and ultimately delivers high-quality 3D box predictions. |
|
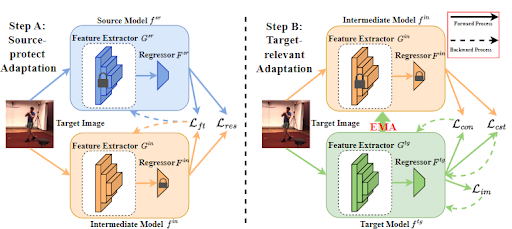
Qucheng Peng, Ce Zheng, Chen Chen. IEEE/CVF International Conference on Computer Vision (ICCV), 2023 paper / Code we propose source-free domain adaptive HPE, which aims to address the challenges of cross-domain learning of HPE without access to source data during the adaptation process. |

|
Ce Zheng, Matias Mendieta, Chen Chen. ICCV Workshop, 2023 paper / code we propose a two-stream Pyramid crOss-fuSion TransformER network (POSTER) for facial expression recognition. |

|
Ce Zheng, Xianpeng Liu, Guo-Jun Qi, Chen Chen. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023 paper / project page A lightweight pure transformer architecture named POoling aTtention TransformER (POTTER) for the HMR task from single images. |

|
Ce Zheng, Matias Mendieta, Taojiannan Yang, Guo-Jun Qi, Chen Chen. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023 paper / project page An efficient transformer-based method for human pose estimation and mesh reconstruction. |
|
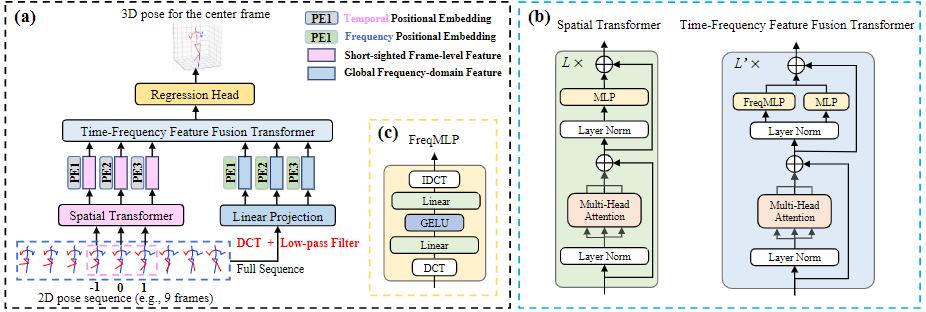
Qitao Zhao, Ce Zheng, Mengyuan Liu, Pichao Wang, Chen Chen. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023 paper / project page An extension of our PoseFormer paper to improve robustness. |
|
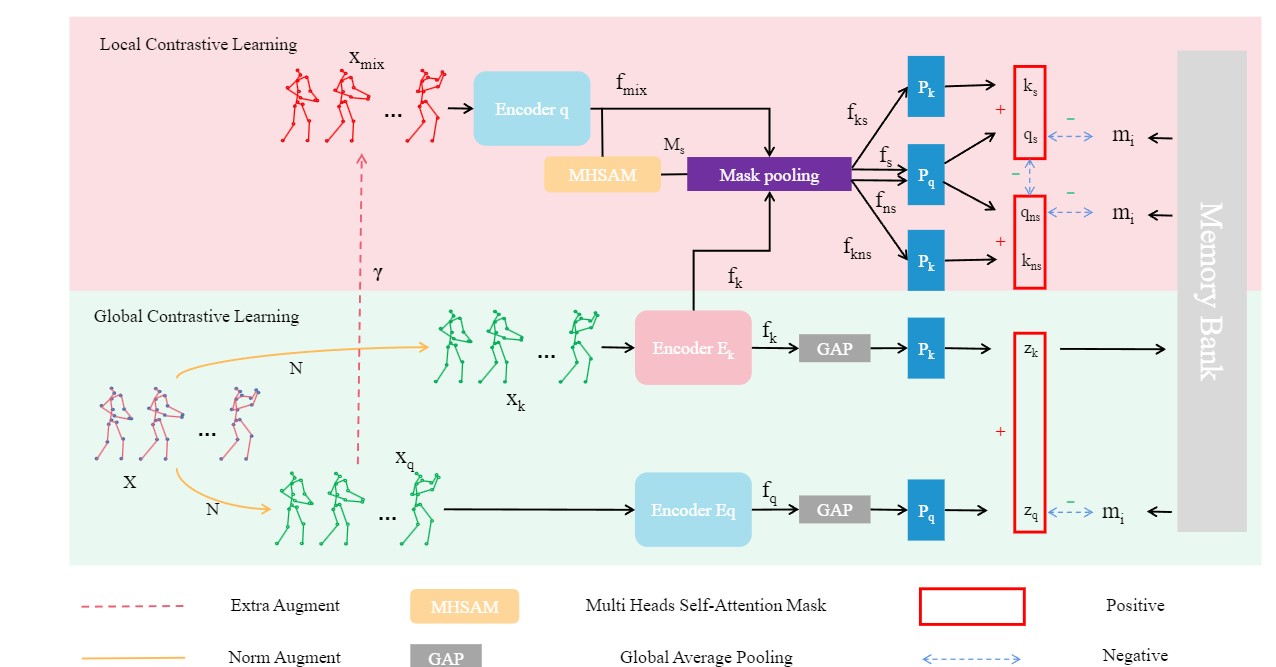
Yilei Hua, Wenhan Wu, Ce Zheng, Aidong Lu, Mengyuan Liu, Chen Chen, Shiqian Wu. The International Joint Conference on Artificial Intelligence (IJCAI) , 2023 paper / code SkeAttnCLR: An attention-based contrastive learning framework for skeleton representation learning. |
|
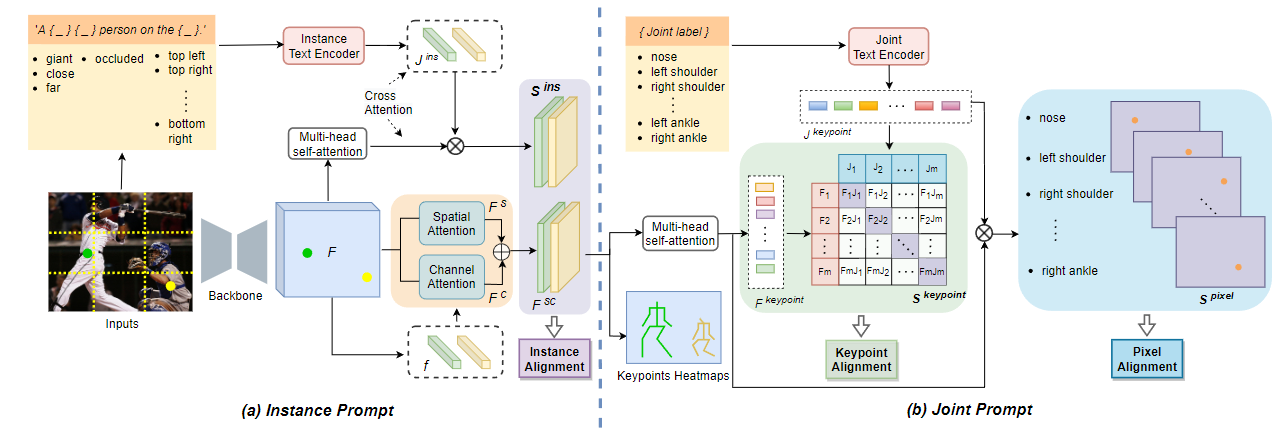
Shengnan Hu, Ce Zheng, Zixiang Zhou, Chen Chen, Gita Sukthankar. The IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , 2023 paper / code An end-to-end pipeline that leverages both instance and joint cues from the language model for occluded pose estimation. |

|
Ce Zheng, Matias Mendieta, Pu Wang, Aidong Lu, Chen Chen. ACM International Conference on Multimedia(ACM MM), 2022 paper / code A lightweight pose-based method that can reconstruct human mesh from 2D human pose |
|
Ce Zheng, Sijie Zhu, Matias Mendieta, Taojiannan Yang, Chen Chen, Zhengming Ding. IEEE/CVF International Conference on Computer Vision (ICCV), 2021 paper / code PoseFormer: a spatial-temporal transformer (the first transformer-based) structure for 3D human pose estimation in videos. |
|
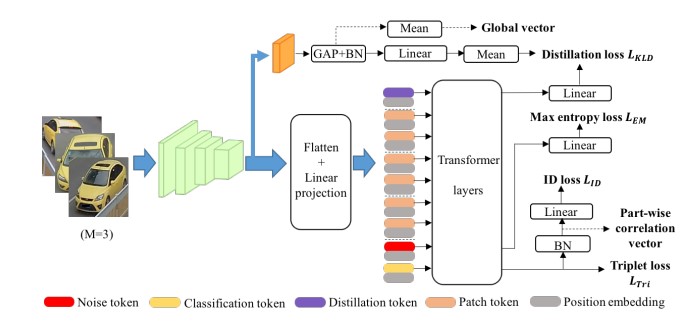
Ming Li, Jun Liu, Ce Zheng, Xinming Huang, Ziming Zhang. IEEE Transactions on Multimedia (TMM) , 2021 paper / The first transformer-driven framework to capture comprehensive instance codes from multiple view images for vehicle ReID. |
|
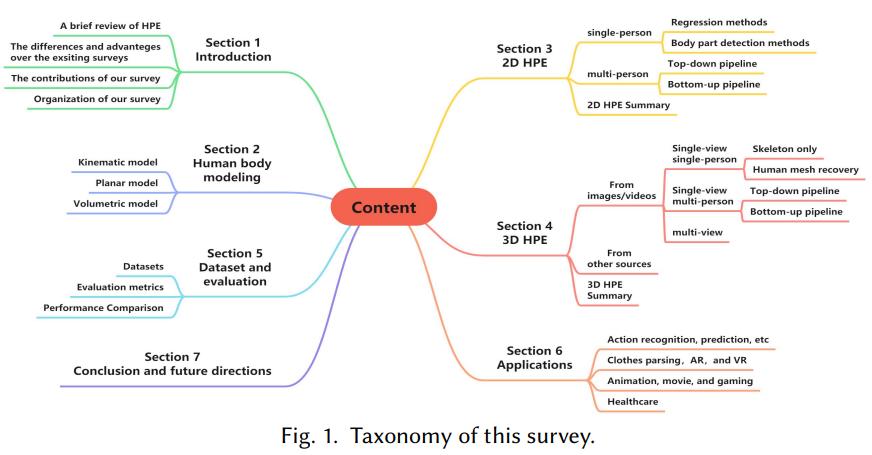
Ce Zheng*, Wenhan Wu*, Chen Chen, Taojiannan Yang, Sijie Zhu, Ju Shen, Nasser Kehtarnavaz, Mubarak Shah. (ACM Computing Surveys, IF=14.32 ), 2023 paper / Project page A comprehensive survey for 2D and 3D Human Pose Estimation. |
|
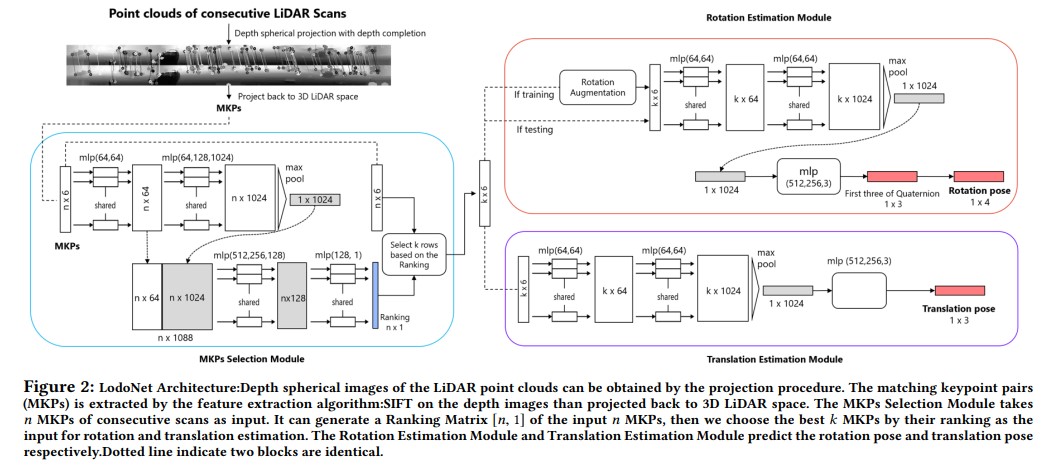
Ce Zheng, Yecheng Lyu, Ming Li, Ziming Zhang. ACM International Conference on Multimedia(ACM MM), 2020 paper / A new approach that extracts the matched 2D keypoint pairs(MKPs) for 3D LiDAR Odometry. |
|
|
 |
Aera Chair: NeruIPS 2025, ACM Multimedia 2025, 2026
Reviewer: TPAMI, IJCV, TIP, TCSVT, CVIU, TNNLS, Neurocomputing, Neural Networks Reviewer: CVPR, ICCV, NeurIPS, ICLR, SIGGRAPH Asia, ACM Multimedia, |
|
Feel free to steal this website's source code. Do not scrape the HTML from this page itself, as it includes analytics tags that you do not want on your own website — use the github code instead. Also, consider using Leonid Keselman's Jekyll fork of this page. |